数据科学 - 客户流失预测:基于随机森林的分析与优化
项目概述
本项目旨在帮助PowerCo(一个大型公用事业公司,提供电力和天然气服务)解决客户流失的问题。PowerCo面临的主要挑战是中小型企业(SME)客户的流失,尤其是在当前充满竞争的能源市场中。为了帮助PowerCo更好地理解客户流失的原因,我们的目标是识别导致客户流失的关键因素,并提出改进客户留存率的具体建议。
在这个项目中,我们将通过数据科学的方法,结合探索性数据分析(EDA)、特征工程和机器学习模型,帮助PowerCo识别流失的驱动因素。最终,我们将构建一个客户流失预测模型,并提出基于数据驱动的建议,帮助PowerCo提高客户留存率。
Task 1:业务理解与假设框架
在项目的初期阶段,我们的任务是将PowerCo面临的业务问题转化为数据科学问题,并为后续的分析设立清晰的假设框架。
业务问题定义
PowerCo正在面临越来越多的客户流失问题,尤其是在中小型企业(SME)领域。为了找出客户流失的根本原因,我们需要回答以下几个关键问题:
- 流失的原因是什么? 客户流失可能受到多个因素的影响,如产品定价、产品差异化、客户服务质量等。
- 有哪些因素会导致客户选择更换能源供应商? 是否有某些特定因素(如价格敏感度)对客户流失有更大的影响?
假设框架
在初步了解了业务问题后,我们根据行业知识和前期调研,提出了以下假设,作为后续分析的方向:
- 产品差异化不足:如果PowerCo的产品与其他供应商差异不大,客户可能会更容易转向价格更具竞争力的其他供应商。
- 客户服务差:差的客户服务可能会导致客户的不满和流失。提高客户服务质量或许是减少流失的有效措施。
- 定价问题:客户流失可能与价格敏感度相关,即如果客户觉得其他供应商提供更具吸引力的价格,他们可能会选择换供应商。
基于这些假设,我们将通过数据分析来验证这些因素是否确实是流失的关键驱动因素。
数据科学任务
将业务问题转化为数据科学问题,我们的主要任务包括:
- 收集和分析数据:我们将需要从PowerCo收集历史客户数据、定价数据和客户流失数据。
- 建立假设并进行验证:通过数据分析验证上述假设,评估哪些因素对客户流失的影响最大。
- 模型设计:基于数据分析结果,我们将构建预测模型,用于预测哪些客户更可能流失。
Task 2:探索性数据分析(EDA)
任务目标
我们的目标是通过探索性数据分析(EDA)深入了解PowerCo的客户数据和定价数据,并识别可能影响客户流失的关键因素。通过对数据的初步分析,我们将能够发现潜在的趋势、模式以及异常值,为后续的建模和特征工程工作打下基础。
数据集概述
我们使用了两个主要的数据集:client_data.csv 和 price_data.csv。这些数据集包含了PowerCo的客户信息、消费行为以及电力和功率价格等信息。
client_data.csv
这个数据集包含了PowerCo的客户信息,主要字段如下:
- id: 客户公司唯一标识符
- activity_new: 客户公司活动类别
- channel_sales: 销售渠道的代码
- cons_12m: 过去12个月的电力消费量
- cons_gas_12m: 过去12个月的天然气消费量
- cons_last_month: 上个月的电力消费量
- date_activ: 合同激活日期
- date_end: 合同结束日期
- date_modif_prod: 上次产品修改日期
- date_renewal: 下一次合同续约日期
- forecast_cons_12m: 预测的未来12个月电力消费量
- forecast_cons_year: 预测的未来1年电力消费量
- forecast_discount_energy: 当前电力折扣的预测值
- forecast_meter_rent_12m: 未来12个月的电表租赁费用预测
- forecast_price_energy_off_peak: 预测的1号时段(非高峰时段)电价
- forecast_price_energy_peak: 预测的2号时段(高峰时段)电价
- forecast_price_pow_off_peak: 预测的1号时段(非高峰时段)功率价格
- has_gas: 是否为天然气用户
- imp_cons: 当前已支付的电力消费量
- margin_gross_pow_ele: 电力订阅的毛利
- margin_net_pow_ele: 电力订阅的净利
- nb_prod_act: 活跃产品和服务的数量
- net_margin: 总净利润
- num_years_antig: 客户的历史年数(即客户的老化度)
- origin_up: 客户首次订阅的电力营销活动的代码
- pow_max: 订阅的最大功率
- churn: 客户是否在未来3个月内流失(流失标识)
price_data.csv
这个数据集包含了每个客户的电力和功率价格数据,涵盖了不同时间段的电价情况。主要字段如下:
- id: 客户公司唯一标识符
- price_date: 参考日期
- price_off_peak_var: 1号时段(非高峰时段)的变动电价
- price_peak_var: 2号时段(高峰时段)的变动电价
- price_mid_peak_var: 3号时段(中峰时段)的变动电价
- price_off_peak_fix: 1号时段(非高峰时段)的固定电价
- price_peak_fix: 2号时段(高峰时段)的固定电价
- price_mid_peak_fix: 3号时段(中峰时段)的固定电价
注意: 部分字段为哈希处理的文本字符串,这些字段保持了原始数据的隐私性,但它们仍然保留了商业含义,可能具有预测能力。
数据用途与分析
在探索性数据分析(EDA)阶段,我们将重点分析以下几个方面:
客户消费行为:
通过分析过去12个月的电力和天然气消费量、预测消费量等数据,我们希望识别哪些消费模式可能与客户流失相关。例如,客户是否有突出的消费模式(如在某些月份消费激增),这些模式可能会影响他们是否选择续约或切换到其他供应商。定价因素:
价格是流失的一个潜在驱动因素。我们将分析不同时间段(如高峰时段和非高峰时段)的电力价格如何影响客户流失。特别是,对于价格敏感的客户,价格的波动可能会直接影响他们的流失决定。客户服务与合约信息:
客户的合约信息(如合同开始和结束日期、产品修改日期、续约日期等)可能揭示出客户是否有重新评估服务的趋势。如果客户接近合同结束日期或者没有及时续约,他们可能更容易流失。因此,我们将分析这些时间相关特征对客户流失的影响。流失率分析:
我们将计算流失率,并检查不同特征(如消费水平、价格敏感度、合同类型等)与流失率之间的关系。这将帮助我们识别出哪些特征在预测客户流失方面更为重要。异常值与数据清洗:
在EDA过程中,可能会遇到数据中的异常值或缺失值。我们将通过描述性统计分析(如均值、中位数、标准差)和可视化手段(如箱型图)来识别这些问题,并采取相应的措施进行处理。
探索性数据分析(EDA)
在任务2中,我们使用了探索性数据分析(EDA)来对PowerCo的客户数据和定价数据进行深入分析。以下是我们分析的关键内容和得出的结论。
1. 数据加载和描述性统计
首先,我们加载了client_data.csv和price_data.csv数据,并进行了基本的描述性统计分析。通过查看数据的结构和每个字段的类型,我们可以了解数据的基本情况。
- 客户数据(
client_data.csv)包含26列,其中包括客户的消费数据、合同信息和是否流失的标识。 - 价格数据(
price_data.csv)包含7列,主要是关于不同时间段电价的数据。
我们注意到,日期相关的字段目前并非日期格式,这意味着我们在后续处理中需要将这些字段转换为适当的日期格式。
2. 主要分析内容
在EDA中,我们分析了以下几个关键领域:
客户流失分析
我们计算并可视化了客户流失的比例。结果显示,大约10%的客户发生了流失,这为我们后续的分析提供了一个基准。
1 | |
销售渠道的流失分布
我们分析了不同销售渠道的客户流失情况,结果显示,流失客户分布在多个销售渠道中,尤其是MISSING值对应的渠道流失率为7.6%。这表明,数据清洗过程中MISSING值可能隐含了某些有用的信息,值得在建模时进一步关注。
1 | |
客户消费分析
我们检查了客户过去12个月的电力和天然气消费数据,并通过直方图展示了它们的分布。消费数据呈高度正偏态,显示出在高消费值附近有较长的右尾,这表明存在大量极值或异常值。
1 | |
价格敏感度分析
我们分析了电力的预测价格(高峰和非高峰时段),并观察价格波动对客户流失的潜在影响。该分析有助于确定价格是否为客户流失的主要驱动因素。
1 | |
合同类型和客户流失
我们进一步分析了客户是否使用天然气服务对流失的影响。结果表明,天然气客户的流失率较低,这表明多产品套餐可能有助于提高客户的留存率。
1 | |
毛利和净利分析
通过分析电力订阅的毛利和净利,我们发现有部分客户的毛利和净利值非常高,这可能表示他们是高价值客户。我们将在特征工程阶段进一步分析这些客户的行为。
1 | |
结论
从EDA中,我们得出了以下结论:
- 流失率:大约10%的客户流失,这为后续的模型提供了基准。
- 消费行为:消费数据偏斜,需要在特征工程中进行调整。
- 销售渠道:不同的销售渠道具有不同的流失率,其中
MISSING销售渠道的流失率特别高。 - 价格敏感度:虽然电力价格波动对流失有一定影响,但价格并非最主要的流失因素。
- 多产品套餐:使用天然气的客户流失率较低,表明跨产品套餐可能有助于减少流失。
Task 3:特征工程
我们进行了特征工程,以增强预测模型的表现,并为后续建模提供了更有用的数据特征。特征工程包括创建新的特征、处理缺失值、数据转换以及特征的编码。以下是详细的过程和结论。
1. 创建价格差异特征
我们首先关注了电价的变化,尤其是12月与前1月之间的电价波动。电价波动可能是客户流失的重要原因。我们通过以下步骤创建了新的特征:
- 步骤1:将电价数据按公司和日期进行分组,计算每个月的平均电价。
- 步骤2:提取1月和12月的数据,并计算这两个月之间的电价差异。
- 计算了
offpeak_diff_dec_january_energy(电力价格的电能差异)和offpeak_diff_dec_january_power(电力价格的功率差异)这两个新特征。
- 计算了
结论
通过分析这些价格差异特征,我们发现价格波动对客户流失可能具有显著影响。客户可能因价格大幅波动而选择离开,因此这些特征为流失预测提供了有价值的信息。
2. 计算时间段内的平均价格变化
除了价格差异,我们还计算了不同时段之间的平均价格差异。这些时段包括off_peak、peak和mid_peak,每个时段的价格变化对客户的影响不同。我们计算了以下特征:
off_peak_peak_var_mean_diff:计算off_peak和peak时段的平均电价差异。peak_mid_peak_var_mean_diff:计算peak和mid_peak时段的平均电价差异。off_peak_mid_peak_var_mean_diff:计算off_peak和mid_peak时段的平均电价差异。- 同样地,对于固定价格时段,我们也计算了类似的特征。
结论
通过这些细化的价格变化特征,我们能够捕捉到每个时间段的电价波动,这些波动可能会影响客户的行为。例如,若某一时段的电价上涨较多,客户可能会更倾向于寻找其他电力供应商,因此这些特征可能有助于预测客户流失。
3. 计算最大价格变化
在此基础上,我们还计算了每个月电价的最大变化,进一步捕捉那些可能导致客户流失的异常波动。例如,若某个月的价格突然大幅上涨,客户可能会选择离开。以下是创建的特征:
off_peak_peak_var_max_monthly_diff:计算每个月在off_peak和peak时段的最大价格差异。peak_mid_peak_var_max_monthly_diff:计算每个月在peak和mid_peak时段的最大价格差异。off_peak_mid_peak_var_max_monthly_diff:计算每个月在off_peak和mid_peak时段的最大价格差异。
结论
这些最大价格变化特征帮助我们捕捉到价格波动的极端情况,这对客户的流失决策有着重要的影响。例如,突然的价格大幅上升可能会让客户更加倾向于跳槽到其他供应商,因此这些特征可能对流失预测有着重要的作用。
4. 创建客户任期特征
客户的任期(即客户与公司建立关系的时间)是另一个重要的特征。我们通过计算客户的任期(以年为单位)来创建了tenure特征。我们发现,客户的任期与流失率之间存在一定的关系:
- 客户的任期越短,其流失的可能性越大,尤其是在客户刚开始使用服务时。
- 对于任期较长的客户,流失的可能性相对较小。
结论
较短的客户任期与较高的流失率相关,因此,tenure特征对于预测流失具有重要价值。
5. 处理日期特征
我们对日期特征进行了处理,转换为与特定参考日期的差异(以月为单位)。具体来说,我们创建了以下特征:
months_activ:客户自激活日期以来的月数。months_to_end:客户合同剩余的月数。months_modif_prod:自上次产品修改以来的月数。months_renewal:自上次合同续签以来的月数。
这些特征有助于捕捉客户与公司之间的关系以及他们对合同变化的反应。
结论
这些日期特征可以帮助我们了解客户的生命周期和与公司的关系。例如,接近合同到期的客户可能会开始寻找更优惠的供应商,因此这些特征有助于流失预测。
6. 转换布尔数据
我们将“has_gas”字段(表示客户是否同时使用电力和天然气服务)从布尔值转换为二元特征。结果显示,使用天然气的客户流失率较低,因此has_gas成为了一个重要的特征。
结论
“has_gas”特征揭示了客户是否拥有多个服务,而多服务客户的流失率相对较低,这为流失预测提供了有价值的信息。
7. 类别数据编码(Categorical Data Encoding)
在特征工程中,大多数机器学习算法不能直接处理字符串类型的数据。因此,我们需要将类别数据转换为模型能够理解的数值类型。常见的做法有两种:标签编码(Label Encoding) 和 独热编码(One-Hot Encoding)。
在这个任务中,我们主要使用了独热编码(One-Hot Encoding),以下是针对两个重要类别数据的处理:
7.1. channel_sales(销售渠道)
这个特征是一个字符串类型的变量,它表示客户的销售渠道。为了让模型能够处理这个变量,我们将其转换为多个二元(0或1)特征,这样每个独特的销售渠道都对应一个新特征。使用pandas的get_dummies方法进行独热编码后,每个唯一的channel_sales值都会变成一个新的二元特征。如果客户来自某个销售渠道,则为1,否则为0。
7.2. origin_up(原始营销活动)
类似于channel_sales,origin_up也是一个类别变量,表示客户最初参与的营销活动。为了将它转化为数值特征,我们同样使用了独热编码。每个唯一的营销活动值将成为一个新的二元特征,标示出该客户是否参与了特定的营销活动。
结论
通过 One-Hot Encoding,我们成功地将类别数据转换为数值数据,并避免了由于类别间不合适的顺序关系而可能引入的问题(比如将类别映射为数字时赋予了错误的顺序)。同时,删除频次过低的类别特征,也提高了模型的计算效率。
8. 数值数据的转换(处理偏态分布)(Handling Skewness in Numerical Data)
在分析数据时,我们发现一些特征的呈偏态分布(Skewed Distribution),尤其是消费类特征,如cons_12m、cons_gas_12m、forecast_cons_12m等。对于偏态分布的特征,很多机器学习模型(特别是线性模型)可能会受到影响,因为它们通常假设数据接近正态分布。为了解决这一问题,常见的处理方法是对这些数据进行对数转换(Log Transformation)。
对数转换的实现
我们对以下特征进行了对数转换:
cons_12m(过去12个月的电力消费量)cons_gas_12m(过去12个月的天然气消费量)cons_last_month(上个月的电力消费量)forecast_cons_12m(未来12个月的电力消费预测)forecast_cons_year(未来一年的电力消费预测)forecast_meter_rent_12m(未来12个月的计量仪器租赁费)
对数转换时,我们添加了常数1(np.log10(df["cons_12m"] + 1)),这样做是为了避免对数零值的出现(因为对数0是无定义的)。
结论
转换后的数据分布更加均匀,且标准差减小,说明数据变得更加稳定,适合用于机器学习模型。
9. 相关性分析(Correlation Analysis)
相关性分析的目的是找出特征之间的关系,以避免模型中出现高度相关的特征(即多重共线性)。如果特征之间的相关性过高,可能会导致模型的误差增大,甚至使得模型变得不稳定。因此,在建模之前,我们通常会对数据进行相关性分析,找出和目标变量(在这个项目中为churn)相关的特征,并剔除那些高度相关的特征。
9.1. 如何进行相关性分析?
我们通过计算所有特征之间的皮尔逊相关系数(Pearson Correlation Coefficient),并绘制相关性热图。相关系数值的范围为[-1, 1],其中:
1表示完全正相关,-1表示完全负相关,0表示没有相关性。
9.2. 特征选择
我们通过热图观察了所有特征之间的相关性。热图显示了以下几种情况:
cons_12m(过去12个月的电力消费量)与其他消费相关的特征(如cons_last_month、forecast_cons_12m)之间有很强的相关性,这表明这些特征在反映客户消费行为时有重复的信息。- 一些特征(如
num_years_antig和forecast_cons_year)与其他特征之间有较强的相关性,这可能会导致模型的多重共线性问题。
基于相关性分析,我们删除了两个冗余特征:
num_years_antig:与其他特征(如tenure)高度相关。forecast_cons_year:与forecast_cons_12m高度相关。
Task 4:建模
在完成了数据预处理和特征工程之后,我们可以开始构建预测模型。根据任务要求,我们将使用 随机森林分类器 来预测客户是否会流失。
数据采样
将数据集分成训练集和测试集的目的是模拟现实场景,通过使用测试集进行预测来评估模型的泛化能力。我们通过将数据集分为 75% 的训练数据和 25%。
1 | |
模型训练
在本任务中,我们使用了 随机森林分类器(Random Forest Classifier)。随机森林属于“集成算法”类别,通过多个决策树组合成一个“森林”。通过训练多个决策树,我们能够提高模型的准确性和鲁棒性。
1 | |
结论:
- 随机森林模型通过构建 1000 个决策树来进行训练。每棵决策树独立训练,且每棵树都会学习到数据的不同部分和不同的模式。通过这种方式,我们能提高模型的泛化能力,并减少过拟合的风险。
模型评估
在训练完模型后,为了评估模型的效果,我们使用了三个常见的评估指标:
- 准确率(Accuracy):正确预测的观察值占总观察值的比例。
- 精确率(Precision):模型将负类错误预测为正类的能力(即避免假阳性)。
- 召回率(Recall):模型识别所有正类的能力。
这三个指标非常重要,因为如果我们只依赖准确率,可能会错过一些潜在的重要信息,尤其是当数据不平衡时。例如,在预测心脏病患者时,假阳性和假阴性都会带来不同的影响,因此精确率和召回率的评估比准确率更为重要。
1 | |
结论:
- 准确率:0.90,模型能够准确预测大部分客户的流失情况。
- 精确率:0.82,模型的精确率较高,意味着在预测流失客户时误判的比例较低。
- 召回率:0.05,召回率非常低,表明模型未能有效地识别出所有的流失客户。尽管精确率较高,但召回率低的原因是模型倾向于预测客户不流失。
这表明模型更擅长识别“非流失”客户,但在流失客户的预测上存在较大改进空间。
模型理解
为了进一步理解模型,我们可以查看每个特征的重要性。特征重要性反映了每个特征在预测中的作用,可以帮助我们理解哪些特征对模型的预测贡献最大。通过RandomForestClassifier提供的feature_importances_方法,我们可以提取每个特征的重要性。
1 | |
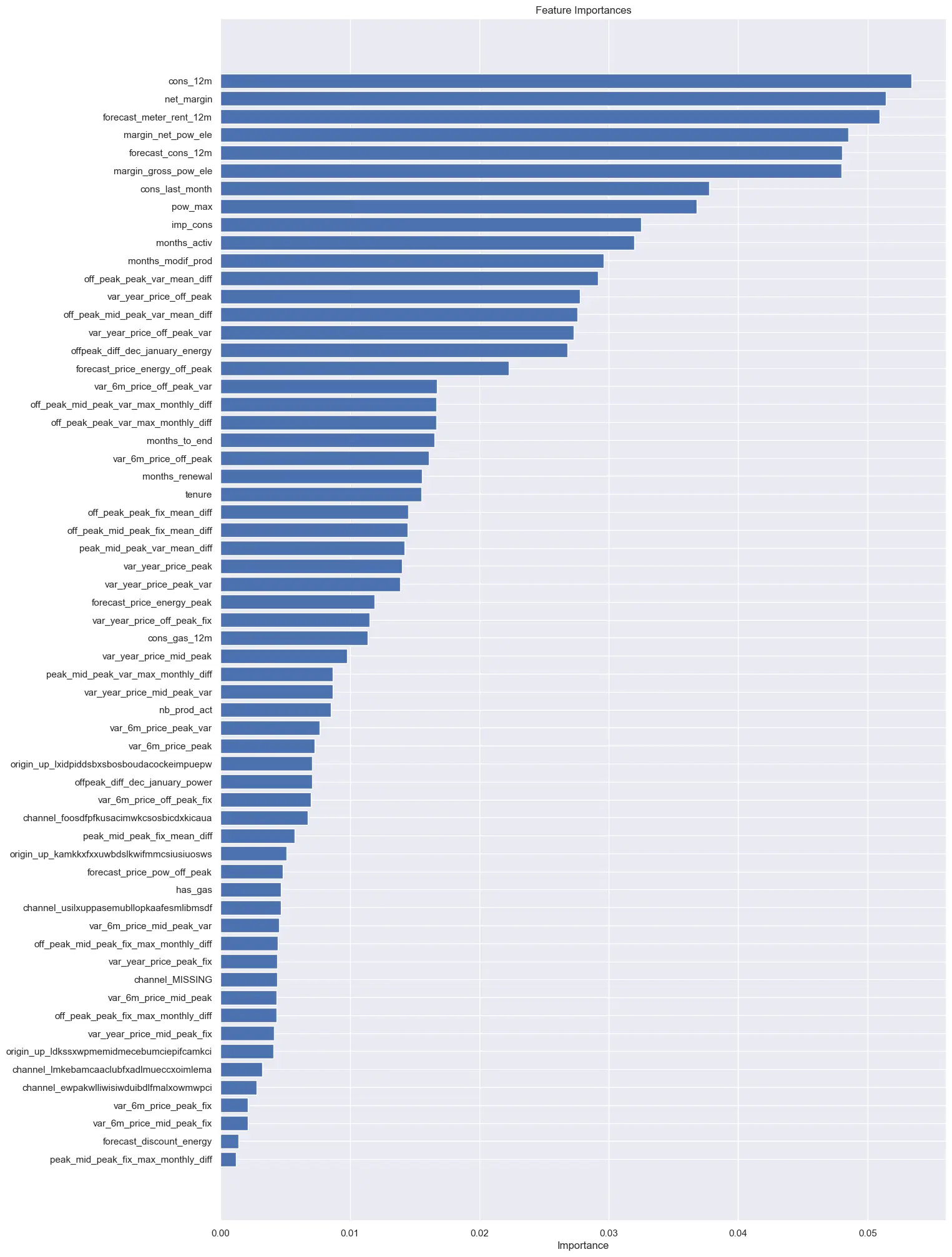
结论:
- 最重要的特征:模型最重要的特征包括净利润、过去 12 个月的消费以及电力订阅的毛利。
- 时间因素:客户的活跃时间(月数)、客户的服务年限以及合同更新的时间也对流失预测有很大影响。
- 价格敏感性:虽然价格敏感性特征(如电力价格)在特征重要性中分布较广,但并不是流失预测的主要驱动因素。
预测概率与结果保存
最后,我们还可以获得每个客户流失的概率,并将其与实际流失结果一起保存,以便后续分析或验证。
1 | |
结论:
- 我们成功地将每个客户的流失概率和实际流失标签保存到
X_test数据集中,生成了最终的预测结果。这些数据可以用于后续分析和决策支持。
总结
通过使用随机森林分类器,我们构建了一个预测客户流失的模型。虽然模型在识别非流失客户方面表现优秀,但在流失客户的预测上还有改进空间。召回率较低提示我们需要进一步优化模型,可能包括重新审视特征工程和模型参数调优。
此外,特征重要性分析帮助我们理解哪些因素对客户流失的预测最为关键,例如净利润、客户活跃时间和电力消费等。
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付