2. 注意力分数
2. Attention Scoring Function
1. 基本思想
- 注意力机制的核心:根据查询(query,
)和键(key, )的相关性分配权重,从所有值(value, )中"加权取信息"。 - 定义:注意力机制通过给每个值
分配权重 ,加权求和得到输出:
-
其中
是 attention 权重,由分数 经过 softmax 得到: 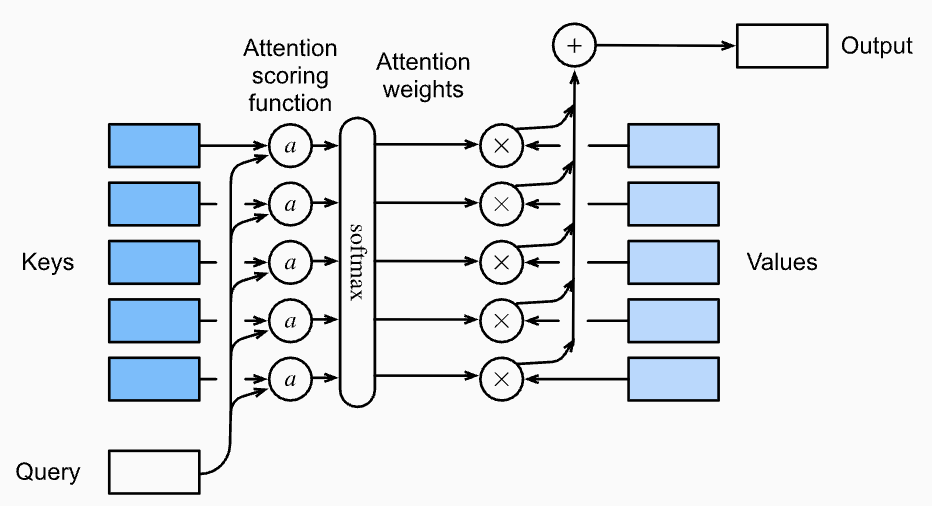
2. 拓展到高维度
- 假设:查询
, 对键值对 ,其中 , 。 - 注意力池化层:
- 注意力分数:
- 其中
是衡量 和 相似度的函数。
3. 常见打分函数
-
加性注意力(Additive Attention)
- 可学习参数:
, , - 打分公式:
- 将
和 连接后输入单隐层 MLP,隐层单元数为 。
- 可学习参数:
-
缩放/点积注意力(Scaled Dot-Product Attention)
-
条件:若
和 长度相同( )。 -
打分公式(未缩放):
-
缩放点积注意力(Transformer常用):
- 归一化防止大数值带来训练不稳定
-
向量化版本:
- 输入:
, , - 注意力评分:
- 注意力池化:
- 输入:
-
4. 总结
- 注意力分数:衡量
和 的相似度,注意力权重是分数的 softmax 结果。 - 两种常见分数计算方式:
- 将
和 合并输入单输出单隐层的 MLP。 - 直接计算
和 的内积(需缩放)。
- 将
参考资料
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付
2. 注意力分数
http://neurowave.tech/2025/04/19/7-2-注意力分数/