3. Bahdanau 注意力(Seq2Seq + Attention)
3. Bahdanau 注意力(Seq2Seq + Attention)
1. 动机
-
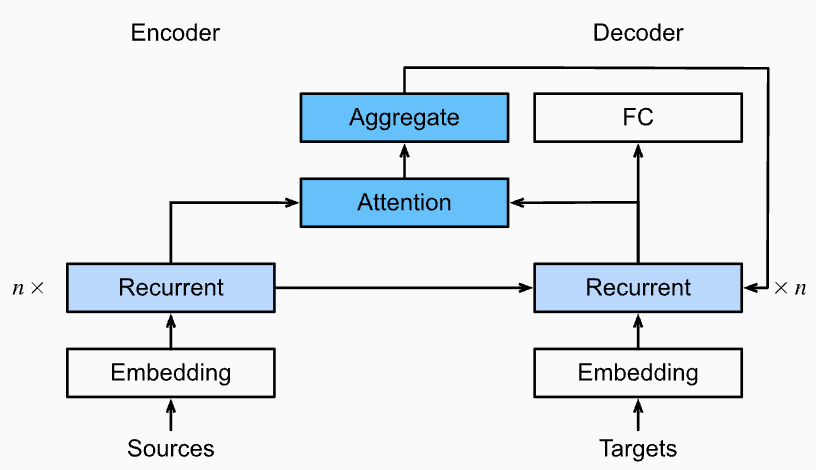
经典 Seq2Seq(编码器-解码器)模型使用两个 RNN:
- Encoder:把整个输入序列"压缩"为一个固定长度的上下文向量(context)。
- Decoder:每一步都依赖这同一个 context 生成下一个输出。
-
局限性:
- 输入句子很长时,固定长度的 context 向量无法承载全部信息,导致信息丢失。
- 实际每个目标词往往只需要关注输入序列的不同部分,而原始 Seq2Seq 总是用同一个 context,缺乏"定位感"。
2. 解决方法:引入 Attention
-
核心思想:
上下文不再固定,而是每一步动态计算,由解码器当前状态(query)和所有编码器输出(key/value)共同决定。 -
工作流程:
-
Encoder 输出序列
(每个词的隐藏状态)。 -
每个解码时刻
,用上一步 Decoder 状态 作为 query,Encoder每个隐藏状态 作为 key 和 value。 -
计算注意力权重
,得到各输入对当前输出的贡献度。 -
动态上下文向量计算公式:
-
与 Decoder 其他输入(如上一步输出)一起,决定 decoder 下一个状态 和生成的输出。
-
3. 总结
- Seq2seq 模型:通过 hidden state 在 Encoder 和 Decoder 间传递信息。
- Bahdanau Attention 能让 Decoder 每一步"自适应"关注输入的关键片段,实现更智能的序列对齐和翻译。
参考资料
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付
3. Bahdanau 注意力(Seq2Seq + Attention)
http://neurowave.tech/2025/04/19/7-3-Bahdanau注意力/