4. Self-Attention 自注意力
4. Self-Attention 自注意力
1. 核心思想
- 自注意力(Self-Attention) 是一种用于序列建模的机制,可以让序列中的每个元素都与其他所有元素建立直接联系,实现对全局依赖的建模。
- 在 NLP、CV 及各种序列任务中,自注意力显著提升了模型对远距离依赖的捕捉能力、并行计算效率和表达力。
2. 基本定义与结构
-
输入:一个长度为
的序列 ,每个元素 。 -
核心步骤:
- 每个输入向量通过不同的线性变换生成查询(query)
、键(key) 、值(value) 。 - 对每个序列元素,计算其 query 与所有 key 的相似度,得到注意力权重。
- 用这些权重对所有 value 加权求和,得到输出
。
- 每个输入向量通过不同的线性变换生成查询(query)
-
数学表达(单头自注意力):
其中
, , 是所有 query、key、value 向量的拼接, 是维度缩放因子。 -
输出:每个位置
的输出 都是全序列的加权和,因此每个 token 能"看到"序列中所有其他 token 的信息。
3. 直观理解
-
自注意力本质上是"信息自助池化"
- 每个位置决定自己从全序列哪里"取信息",关注相关部分,抑制无关内容。
- 例如,句子中"它"可能需要从远处的"猫"那里获得语义信息,自注意力能轻松捕捉这种长距离依赖。
-
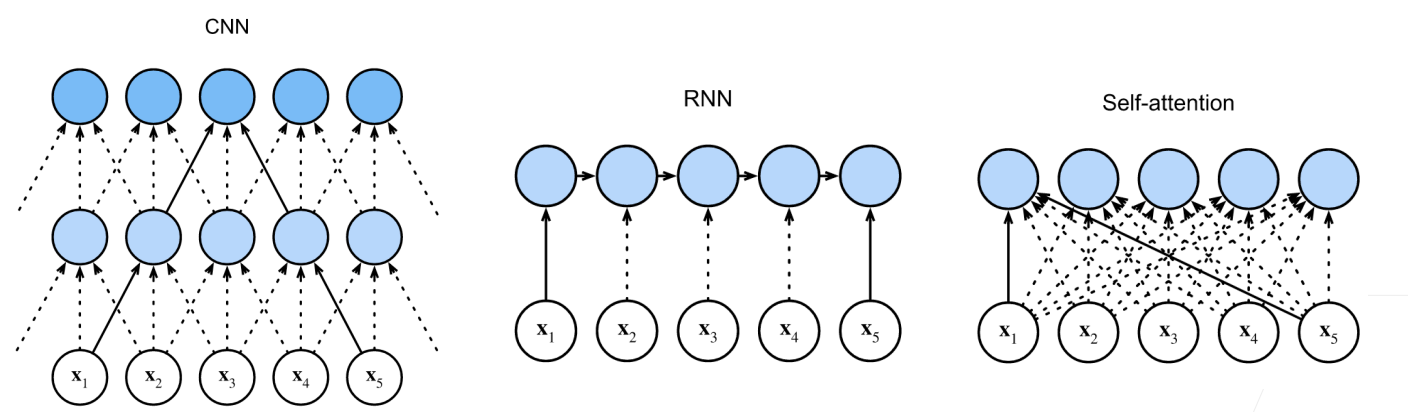
与 CNN / RNN 的对比
CNN RNN 自注意力 计算复杂度 并行度 最长路径 - 自注意力的并行性和最短信息流路径是 transformer 取代 RNN/CNN 的关键原因。
-
位置编码(Positional Encoding)
- 自注意力本身无序列顺序感知能力,所以 transformer 需要引入位置编码(Positional Encoding)补充顺序信息。
- 常用位置编码方法:
- 正弦/余弦编码:不同频率的正余弦函数,将位置
编码为一组向量,加到输入 embedding 上。 - 这样模型可以感知 token 之间的相对或绝对顺序。
- 正弦/余弦编码:不同频率的正余弦函数,将位置
- 位置编码让 transformer 能区分"a b c"和"c b a"。
4. 总结
- 全局建模能力:每个位置可直接获取序列任意部分信息,擅长捕捉长距离依赖。
- 高并行性:所有位置输出可并行计算,显著提升效率。
- 最短路径优势:任意两个 token 之间仅需一步信息传递。
- 灵活扩展:支持多头、多层堆叠结构。
- 缺点:计算与显存消耗为
,长序列处理存在瓶颈。 - 位置编码必不可少:否则丧失顺序感知能力。
参考资料
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付
4. Self-Attention 自注意力
http://neurowave.tech/2025/04/19/7-4-自注意力/