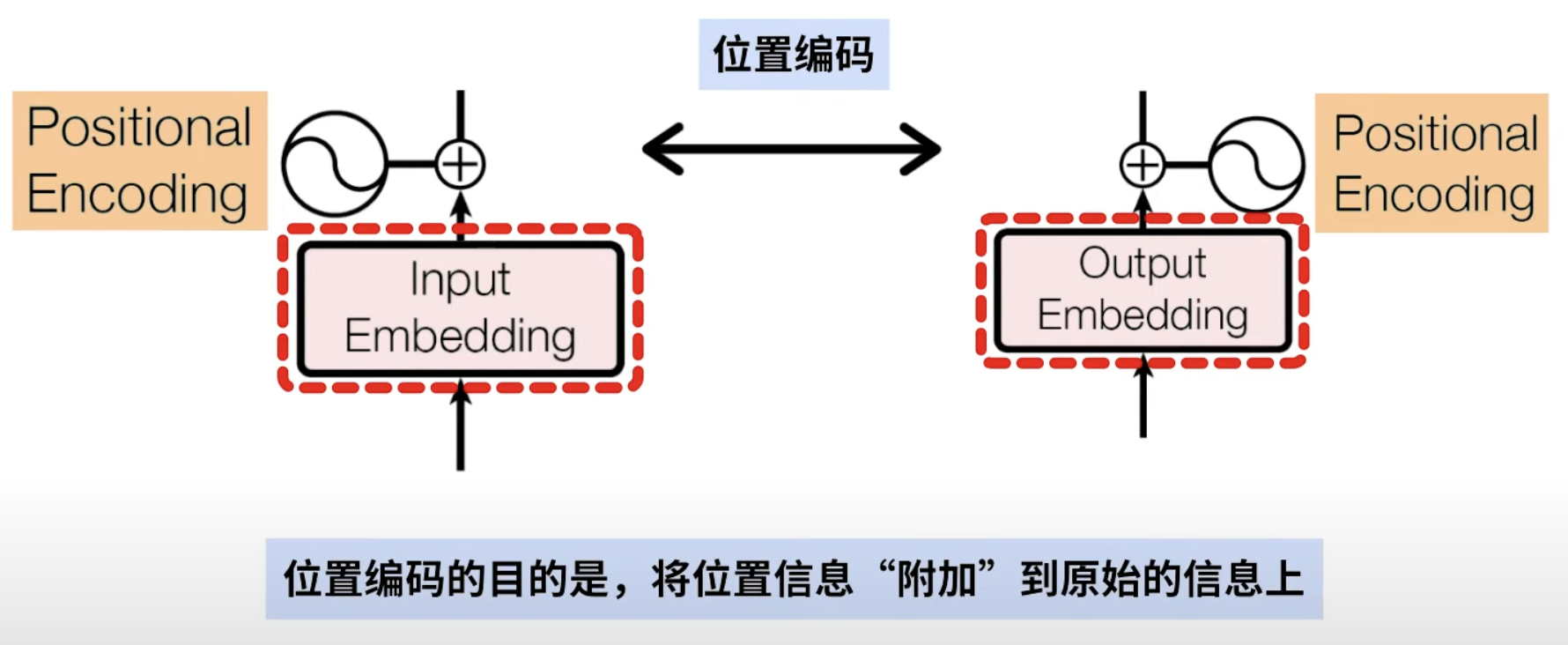
5. Positional Encoding 位置编码
5. Positional Encoding 位置编码
1. 动机
-
为什么要加位置编码?
- Self-Attention 本身不感知输入顺序,把序列当成无序集合(Set),缺乏序列(Sequence)信息。
- 必须人为注入"位置信息",让模型知道"顺序" (Transformer需要)。
-
和其他架构对比:
- CNN 通过卷积核隐式捕捉局部顺序
- RNN 按时间步显式感知顺序
- Transformer 完全依赖位置编码来感知顺序
2. 位置编码的实现
-
基本方法:
- 给长度为
、维度为 的输入 ,为每个位置 添加一个位置向量(位置信息) ,构成位置编码矩阵 ,输入变为 ,从而加入位置信息。。
- 给长度为
-
位置编码矩阵
(正弦-余弦编码): :位置索引 :维度索引的一半 :总维度
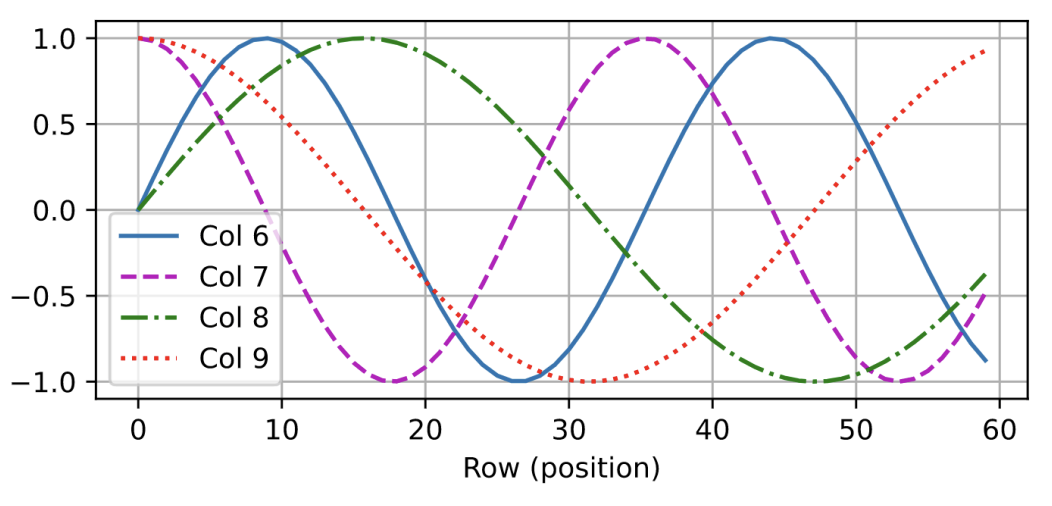
-
绝对位置信息:计算机的二进制编码
-
相对位置信息:
- 有编码的频率参数
,那么, -
:第 个位置的编码的两个分量 -
:第 个位置的编码分量 -
:两个位置之间的距离(如 就是前后相邻) -
这个旋转矩阵(只跟
和 有关)可以把位置 的编码线性投影到任意位置 ,方便模型计算和理解相对位置信息。
-
- 有编码的频率参数
3. 例子:英汉翻译任务中的位置编码
-
英汉翻译任务中的位置编码
- 例如句子"你好吗?",首先会进入词向量层,被转为
的词向量矩阵。

- 然后进行位置编码,将位置信息加到原始词向量上。
- 具体地,用正弦和余弦公式,生成一个
的位置编码矩阵。
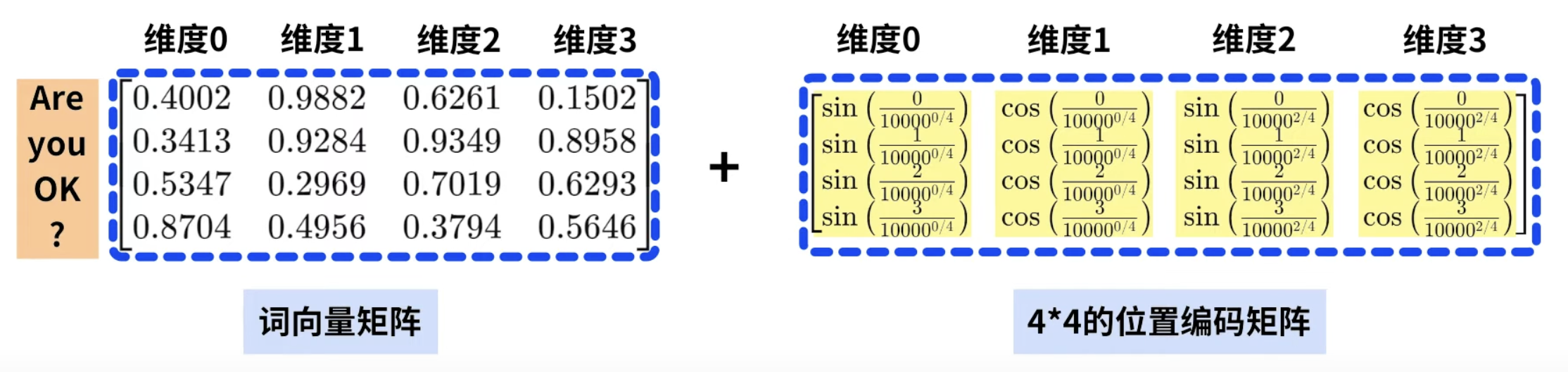
- 将每个词的词向量与对应位置编码直接相加,得到新的输入特征。
- 例如句子"你好吗?",首先会进入词向量层,被转为
-
原理说明:
-
为什么直接加位置编码不会破坏词向量信息?
- 训练数据充足,几乎所有"词+位置"组合模型都能见到并学习。
- 神经网络足够深、参数足够多,能有效区分并利用"词向量+位置编码"的复杂特征。
-
这种方法极大丰富了输入特征空间。例如:有3个词语(
, , )和3个位置编码( , , ),每个词都可以和3个位置组合,得到9种独特的新表示: - 词语向量
- 位置编码向量
- 词
的组合: , , - 词
的组合: , , - 词
的组合: , ,
- 词语向量
-
有一种特殊情况,在数学上称为"碰撞", 不同的词向量和位置编码组合结果,恰好是同一个向量表示(如
)。 这种情况出现时,会使训练数据产生歧义,但是由在高纬度空间, 即使某个维度出现"碰撞",对整个维度来说几乎没有影响。
-
4. 总结
- Self-Attention 层:
- 将
当作 Key、Value、Query 来对序列抽取特征。 - 完全并行,但对长序列计算复杂度高。
- 将
- 位置编码的作用:
- 在输入中加入位置信息,使得 Self-Attention 能记忆位置信息。
参考
李沐《手动深度学习》:自注意力和位置编码
Bilibili:自注意力和位置编码
YouTube:如何理解Transformer的位置编码,PositionalEncoding详解
“觉得不错的话,给点打赏吧 ୧(๑•̀⌄•́๑)૭”

微信支付

支付宝支付
5. Positional Encoding 位置编码
http://neurowave.tech/2025/04/19/7-5-位置编码/